

SenDev: Инозапрет 168-ФЗ — модуль для автоматического контроля иностранных слов на сайте в соответствии с требованиями законодательства РФ. Решение помогает избежать штрафов за использование иностранной лексики там, где существуют русские аналоги.
Преимущества решения:
- Соответствие 168-ФЗ: Алгоритмы проверки настроены на выявление слов, отсутствующих в нормативных словарях РФ.
- Глубокий анализ: Проверка не только по точному совпадению, но и с учетом морфологии (лемматизация), что снижает количество ложных срабатываний.
- Безопасность для продакшена: Пошаговое сканирование не вешает сервер и позволяет прерывать процесс в любой момент.
- Удобный интерфейс: Вся работа ведется из административной панели Bitrix. Есть история сканирований, отчеты и удобный поиск по нарушениям.
- Гибкость: Настройка глубины обхода, исключение путей, игнорирование кода и технических токенов.
- Сканер контента (IBlock, Static, Highload).
- Менеджер словарей (импорт, хранение в БД/файлах).
- Белый список исключений.
- Инструмент быстрой проверки текста.
- ORM-классы для интеграции с внешними системами (таблицы: sendev_inozapret_violation, sendev_inozapret_whitelist и др.).
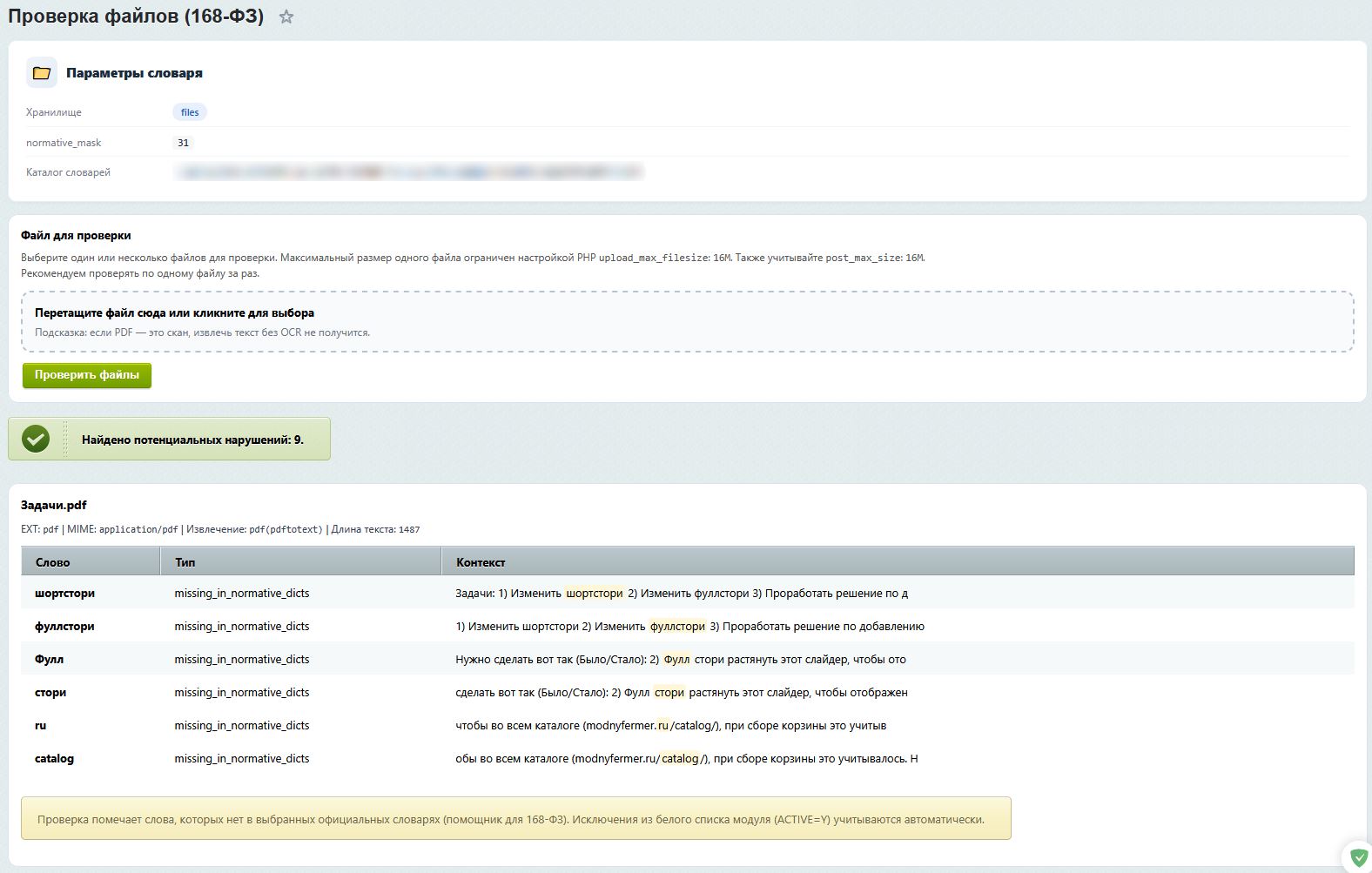
1) Страница для быстрой проверки документов на соответствие нормативным требованиям
Что можно сделать:
Загрузить файлы
Поддерживаются форматы: PDF, DOC, DOCX, TXT, HTML, XLSX. Можно выбрать несколько файлов одновременно или перетащить их в область загрузки.
Получить результат анализа
Система автоматически извлекает текст из документа и проверяет его по словарю запрещённых слов/фраз.
Увидеть найденные нарушения
Если в тексте обнаружены проблемные слова, они отображаются в таблице:
- само слово;
- тип нарушения;
- контекст с подсветкой — чтобы сразу понять, где и как оно используется.
В верхней части страницы отображаются текущие настройки: тип хранилища словаря, маска норматива, путь к файлам словаря.
Получить подсказки при ошибках
Если файл не подошёл по формату, превысил лимит размера или текст не удалось извлечь — система сообщит об этом понятным сообщением.
Для кого этот раздел:
- Редакторы и контент-менеджеры — для проверки материалов перед публикацией;
- Администраторы — для контроля соблюдения требований и диагностики работы модуля.
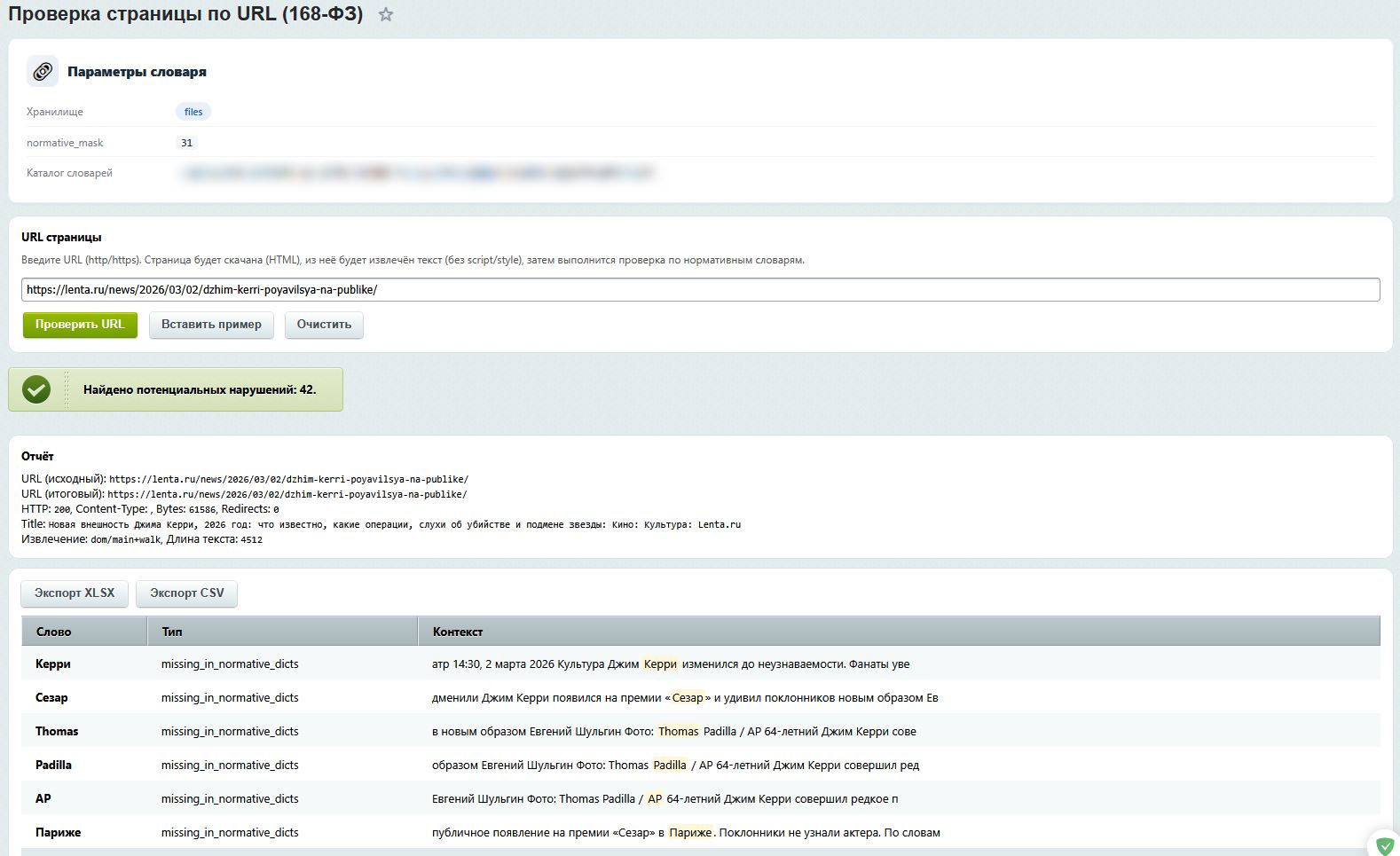
Что можно сделать:
Ввести адрес страницы
Достаточно вставить ссылку (http/https) в поле ввода — система автоматически загрузит и проанализирует содержимое страницы.
Получить отчёт о странице
После проверки отображается служебная информация:
- исходный и финальный URL (после редиректов);
- HTTP-статус, тип контента, размер страницы;
- заголовок страницы и объём извлечённого текста.
Если на странице обнаружены проблемные слова или фразы, они выводятся в таблице:
- само слово/фраза;
- тип нарушения;
- контекст с подсветкой — чтобы сразу увидеть, где и как используется слово.
Результаты проверки можно выгрузить в удобном формате:
- CSV — для открытия в Excel или текстовых редакторах;
- XLSX — полноценный Excel-файл с форматированием.
Кнопки «Пример» и «Очистить» помогают быстро протестировать функционал или начать проверку заново.
Безопасность при проверке:
- Блокируются локальные адреса (localhost, 127.0.0.1, частные сети);
- Разрешены только стандартные порты (80, 443);
- Ограничение на размер загружаемой страницы и длину анализируемого текста;
- Автоматическая обработка кодировок и защита от некорректного контента.
- Редакторы и контент-менеджеры — для проверки публикаций на внешних ресурсах;
- Юристы и специалисты — для контроля соблюдения требований законодательства;
- Администраторы — для аудита контента и экспорта отчётов.
1. Требуется ли доступ к консоли сервера для работы? Нет, модуль полностью работает в рамках PHP-окружения Bitrix. Импорт словаров и сканирование доступны через веб-интерфейс. Подключение phpMorphy опционально для улучшения качества морфологии.
2. Как модуль определяет, что слово является нарушением? Слово считается потенциальным нарушением, если оно не найдено в выбранных нормативных словарях (с учетом лемматизации) и не внесено в белый список. Тип нарушения маркируется как missing_in_normative_dicts.
3. Можно ли сканировать только новый контент? Модуль поддерживает фильтрацию по статусам. При повторном сканировании можно анализировать только измененные данные, однако текущая версия ориентирована на полное или выборочное сканирование по области с сохранением истории статусов (new, fixed).
4. Поддерживается ли работа с мультиязычностью? Интерфейс модуля локализован (RU/EN). Проверка контента ориентирована на русский язык (кириллица), так как закон 168-ФЗ касается использования иностранных слов в русском тексте.
5. Что происходит с найденными нарушениями? Они сохраняются в таблицу базы данных с указанием источника (ссылка на элемент инфоблока или путь к файлу), контекста употребления и даты обнаружения. Вы можете менять их статус на «fixed» после добавления в белый список или правки контента.
6. Есть ли ограничения на размер сайта? Благодаря пошаговому алгоритму (step-by-step) ограничений нет. Вы можете настроить лимит обрабатываемых элементов за шаг в настройках модуля (step_elements, step_files).
7. Как обновлять словари? Предусмотрен механизм импорта готовых словарей через админ-панель. Вы можете заменить файлы в папке модуля или загрузить новые данные в таблицу лемм через интерфейс импорта.
Мы регулярно обновляем содержимое белого списка. Вы можете скачать его на нашем сайте на странице модуля (блок Дополнительные файлы) - https://sendev.ru/solutions/modules/sendev-inozapret-168-fz-kontrol-inostrannykh-slov/
С помощью модуля, вы можете проверить сайт или организовать свой сервис проверки на его основе. Примеры по ссылкам:
- Тексты на иностранные слова в соответствии с 168-ФЗ
- Файлы (PDF, DOC, DOCX, TXT, HTML, XLSX) на иностранные слова в соответствии с 168-ФЗ
- Страницы по URL на иностранные слова в соответствии с 168-ФЗ